Tensor Flow 的 演化历程
整体的发展脉络分为四类
- 跨层深度连接 Depth Connection
- 同层广度连接 Width Connection
- 把层看成动力系统 Continuous-Implicit Flow
- 不同样本/token 走不同路径 Routing Connection
Plain Chain
最原始的信息流就是层的复合,满足 xl+1=Fl(xl,θl), 这样的深层网络的微分就是
∂x0∂xl+1=i=1∏l∂xi∂Fi
Gradient of Loss Function
∂xl∂L=∂xL∂Li=l∏L−1JFi(xi)
Plain Chain 容易出现梯度消失或者梯度爆炸的现象。 随着梯度的模大于0或者小于0,指数发散(爆炸)或者收敛到0(消失)
ResNet
xl+1=xl+Fl(xl,θl)
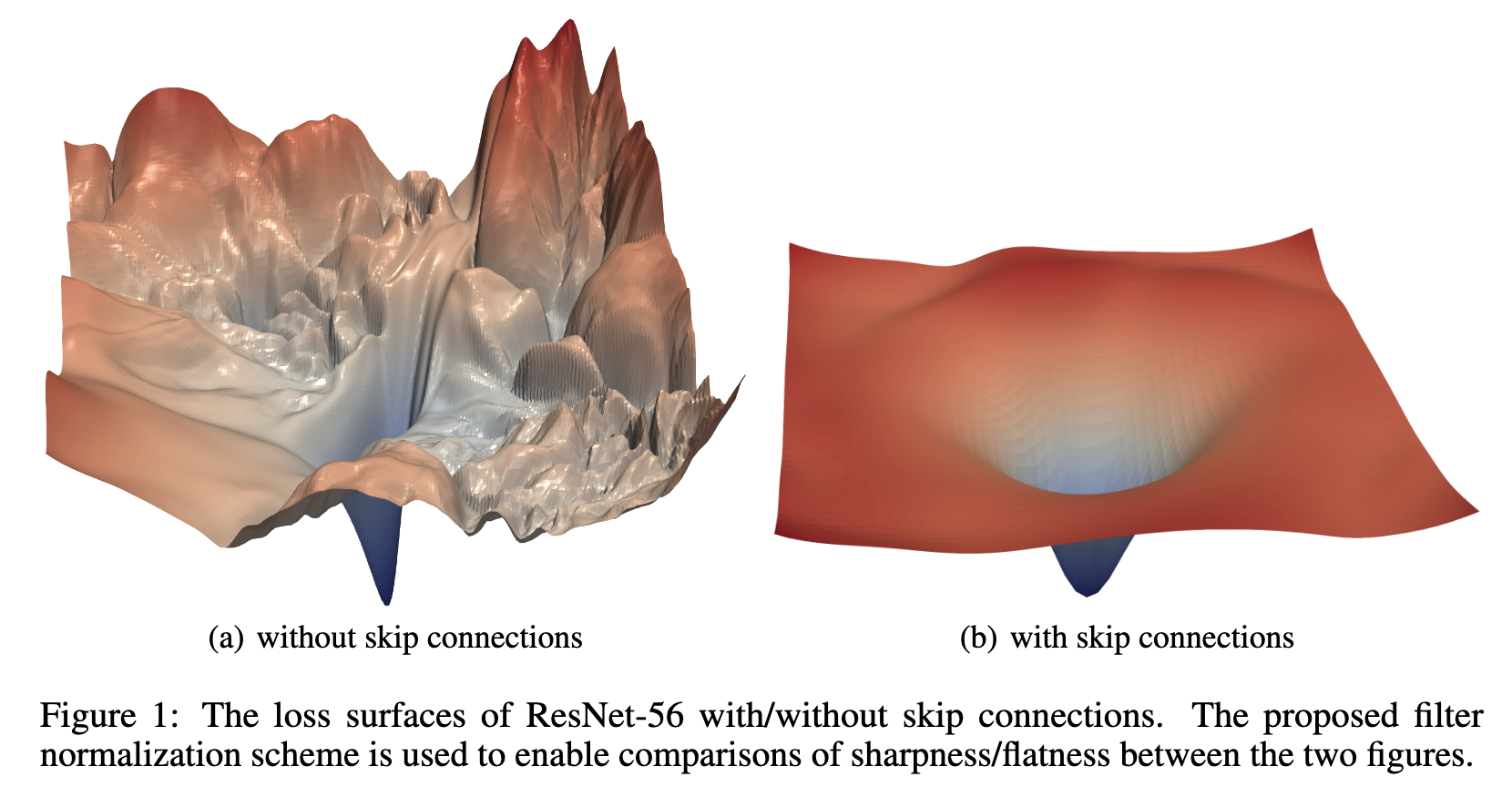
将模型的更新量作为线性可加的残差,将整体的复合非线性映射变为了一个恒等映射+微小扰动量的形式。
DenseNet
DenseNet在ResNet的Skip Connections的基础上,将加性结构换为高维嵌入, 每一层的输入都是前面所有层输出的Concat, 即
xl+1=Fl(Concat[x0,⋯,xl])
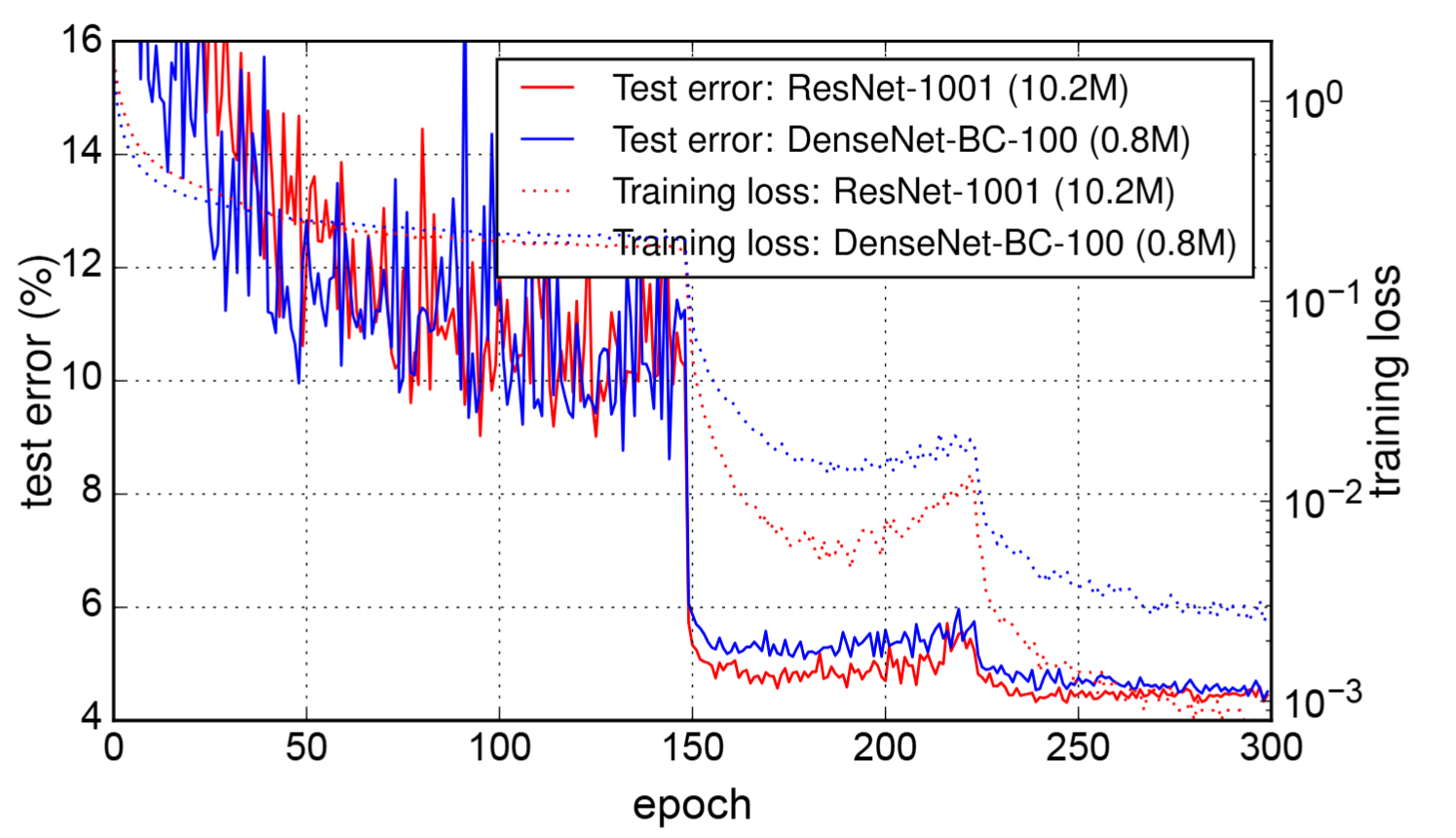
DenseNet的性能开销和维度爆炸无疑是相当恐怖的。在CV领域DenseNet取得了不错的效果,但是在LLM中,其结构无法合适的Scaling-Up
Post-LN、Pre-LN及相关的衍生架构 -- 深度Transformer 中的 residual stream与稳定化
Transformer 中的 Layer Normalization与梯度稳定性 与 DeepNet 对相关的架构进行了讨论。在ResNet的基础结构上,研究LayerNorm的位置对于整体训练的效果、收敛的速度与稳定性的优化
Neural ODE
Deep Equilibrium Model
MoE
MoE 是 Tenor Flow go wider 的结构范式
MoE -- Mixture of experts
Hyper-Connections
本文认为类似于梯度消失/梯度爆炸在深层网络的训练中的问题已经被Post-LN / Pre-LN (Transformer 中的 Layer Normalization与梯度稳定性)解决了,但是二者之间存在对抗性博弈。
- Pre-LN:确实有效解决了梯度消失问题,使得训练极深的网络成为可能。但它带来了表示崩溃(Representation Collapse)——即深层特征变得高度相似,每一层都在做重复工作。
- Post-LN:能缓解表示崩溃,但代价是重新引入了梯度消失,导致训练极不稳定。
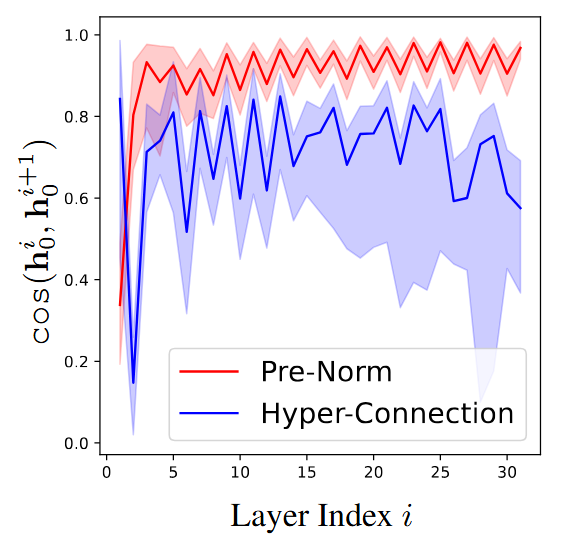
实验结果展示了HC在深层网络中余弦相似度较低的结果,表明HC相比Pre-LN解决了表示崩溃的问题
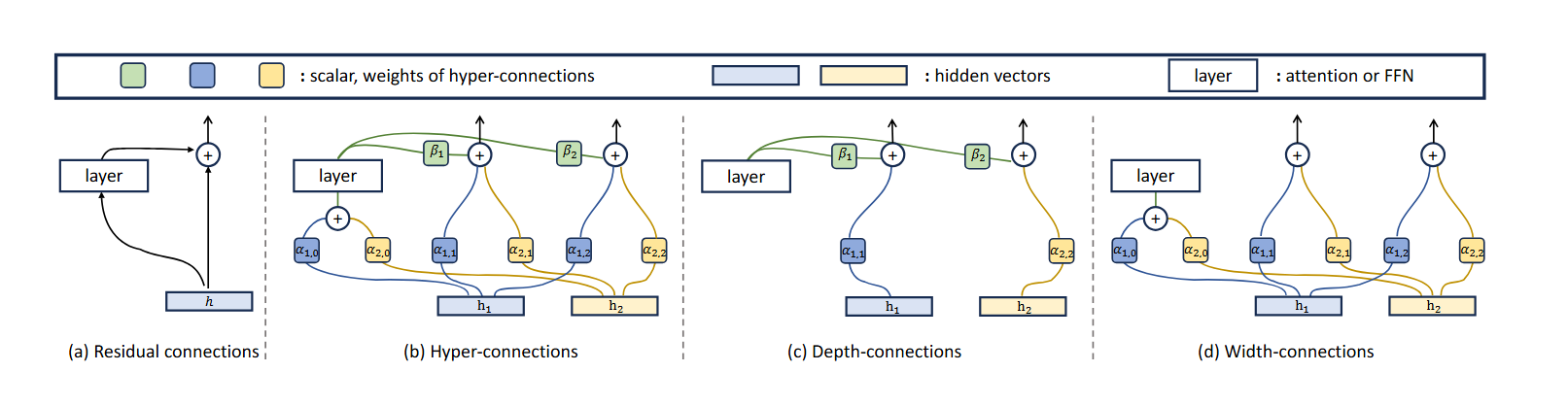
Hyper-Connection 由两个部分拼接而成
- Width-Connections
- Depth-Connections
作为残差链接的横向的和纵向的线性拓展。相当于将n路ResNet 之间嵌入了线性层(如果是SHC则为静态参数线性层,如果是DHC则为可学习的线性层)
Hidden Matrix的不同hidden vector 在初始化时状态是相同的,即满足
H0=(h0,h0,⋯,h0)∈Rn×d
其中hidden vector 的个数n 称为拓展率, 表示 Width-Connections 在横向拓展的维度,这个维度对hidden vector本身的信息量没有影响。
在后续的非线性变换后,不同的hidden vector才变为具有不同意义的vector构成 hidden matrix
由图可以写出层间的残差递推公式, 对于第i 层的残差,有
hi,t+1=∑αj,ihj,t+βiLayer(∑αk,0hk)
用矩阵形式编码相应的参数:
HC=(0AmBAr)=0α1,0α2,0⋮an,0β1α1,1α2,1αn,1β2α1,2α2,2αn,2⋯⋯⋯⋱⋯βnα1,nα2,nαn,n
记第 t 层的残差通道的Layer为 τ,单层的递推写为矩阵方程的形式
Ht+1=BTτ(AmTHt)+ArTHt
Stastic Hyper-Connections
SHC 中的权重矩阵是固定学习的权重矩阵 HC。训练完后,在实际的推理阶段并不会改变相应的参数。
Dynamic Hyper-Connections
DHC 中的权重矩阵依赖于输入的Hidden matrix, 但是并不是类似于在线学习的方式,而是作为Hidden matrix 的函数进行动态输出。
DHC 中在每一个 Hidden Matrix 的输入时都会先进行相应的处理后再输出参数。相应的处理为
⎩⎨⎧Ht=LayerNorm(Ht)B(Ht)=sβ∘tanh(HtWβ)T+BAm(Ht)=sm∘tanh(HtWm)+AmAr(Ht)=sr∘tanh(HtWr)+Ar
相比SHC, 每一个"输出头" 都是一个局部的线性层+ tanh 激活函数的结构
在单次训练中,DHC相比 SHC多训练了线性层,但是换取了更高的信息密度,且这几个线性层的参数量约为 O(dn) , 在模型训练的开销较小的情况下,通过实时生成的非线性权重打破了传统残差连接的表达瓶颈,从而实现了极高的信息利用率和收敛稳定性。
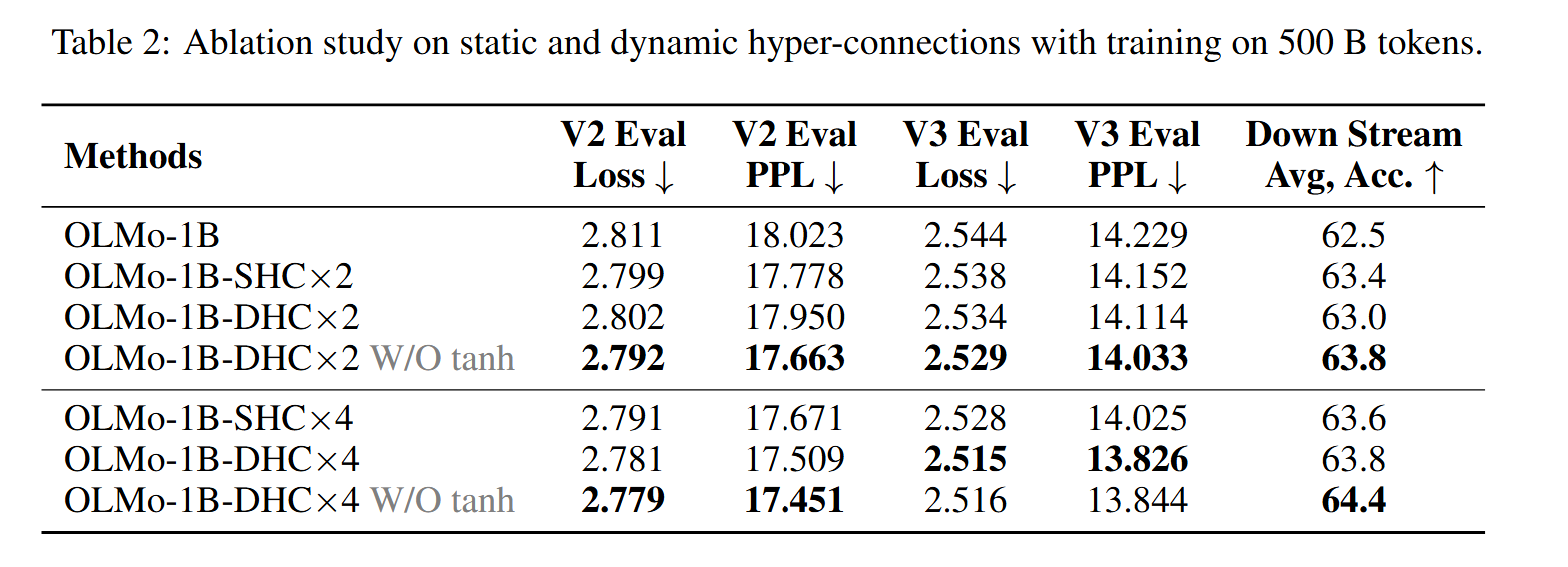
实验证明SHC在小任务的条件下性能与DHC相近,但是在更深的网络、更复杂任务(比如图像生成/大参数LLM预训练)的情况下DHC性能远高于SHC
Manifold-Constrained Hyper-Connections
