DeepNet
本篇文章作为Transformer 中的 Layer Normalization与梯度稳定性的后继文章,进一步进行Layer Normalization的相关学习
Warm-up 与初始化方式对于梯度下降稳定性的影响
在本节设置了三个实验组进行对比
- 对照组1: Post-LN + 标准Xavier初始化 + No Warm-up
- 对照组2: Post-LN + 标准Xavier初始化 + Warm-up
- 对照组3: Post-LN + Xavier缩放初始化 + Warm-up
Xavier的缩放初始化是对于第 l 层,l∈[1,N], 有随着深度递减的缩放因子kl=N+1−l, 使得
Wol∼N(0,kl2d′1)
其采用的评估指标为整个模型各轮训练的输出更新的模, θi 表示第i轮训练后的参数, θ0 表示初始化参数
∥ΔFi∥=∥F(x,θi)−F(x,θ0)∥
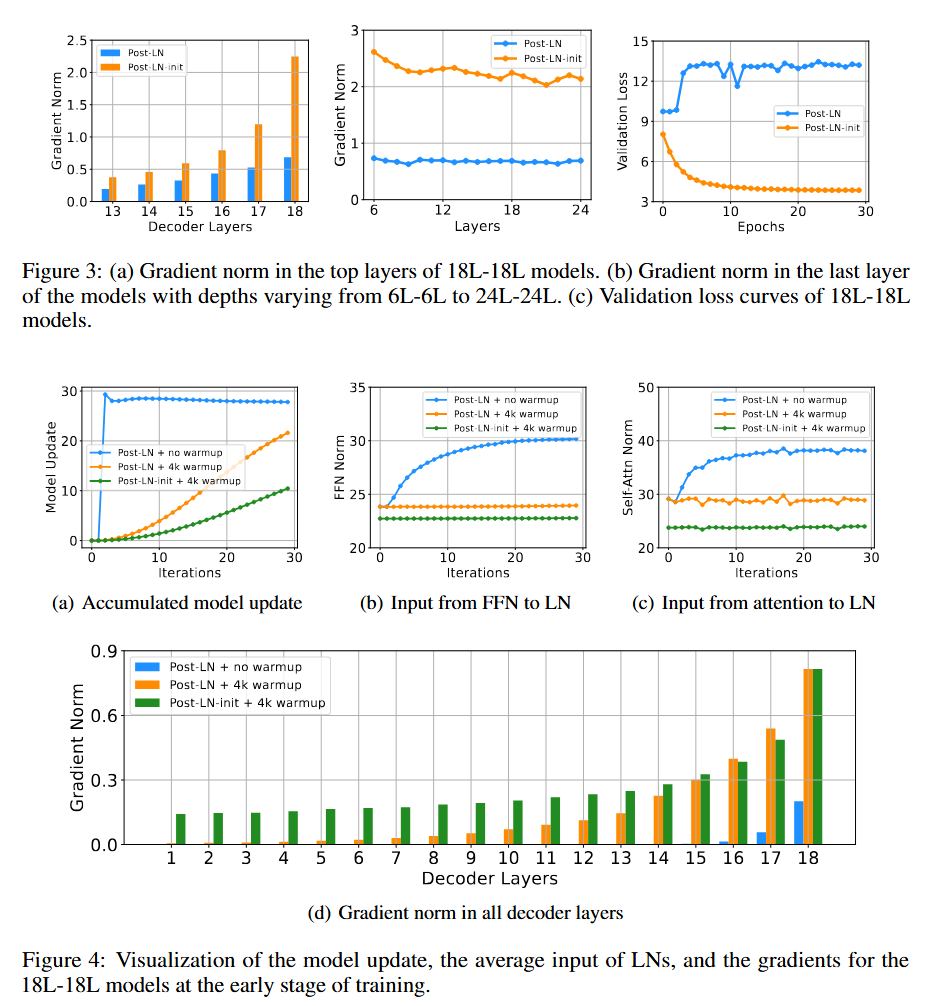
在图4.a中,对照组1 的Model Update在初始步就出现了爆炸。这一结论和 Transformer 中的 Layer Normalization与梯度稳定性 中的结论是一致的。
通过图3的子图对比,作者将Model Update 而非梯度模作为评估梯度下降稳定性的评估指标,因为在对照组2、3的对比中,对照组3的梯度模更大,但是具有更好的收敛效果。
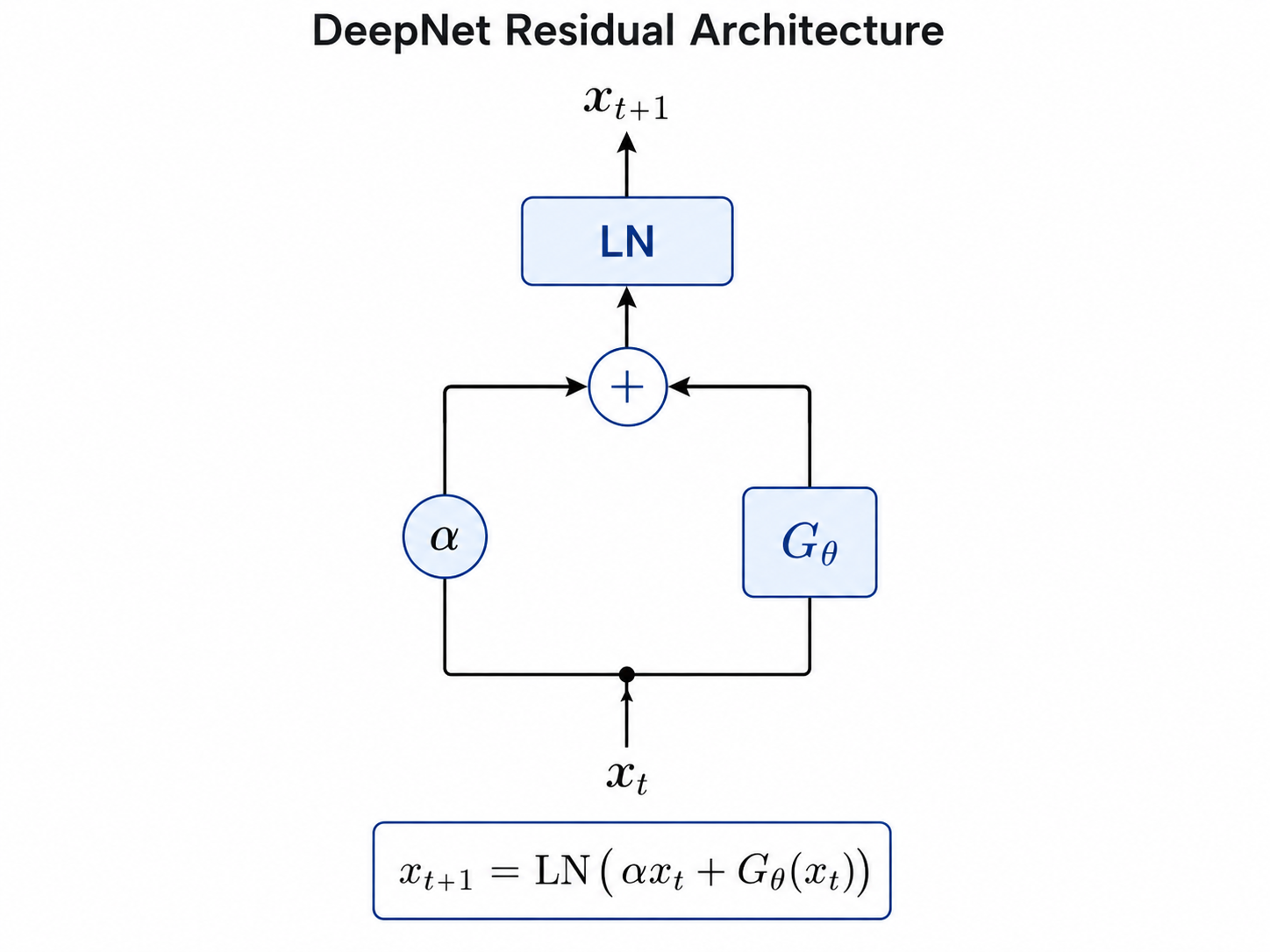
DeepNet 的结构
本文的主体创新点,即DeepNorm 架构。相对于Pre-LN,就是在主输入信号处增加了一个可学习参数 α>1, 对输入tensor进行了放大。
Lemma 1.: 对于 X=(x1,⋯,xn)∈Rn×d, Var(xi)=1,E(xi)=0, qi∈[0,1], 则有
Softmax(q1,⋯,qn)⋅X≍xi
这里的 ≍ 表示 equal bound of magnitude,即只比较数量级上的上下界,而不要求两个向量在方向或逐元素取值上相同。
Proof:
Softmax(q1,⋯,qn)⋅X=(∑expqjexpqi)i⋅(x1,⋯,xn)T=∑∑expqjxiexpqi
由于
n≤∑expqj≤ne
有
∑expqj1=Θ(n1)
因此可以写成凸集的形式
Softmax(q1,⋯,qn)X=i=1∑nwixi,wi=∑expqjexpqi=Θ(n1).
因此,由 wi=Θ(n1) 可得
i=1∑nwixi≍i=1∑nn1xi.
又因为每个 xi 都满足 E(xi)=0 且 Var(xi)=1,所以所有 xi 具有相同的 magnitude bound。于是 n 个同阶向量经过 n1 量级的权重加权求和后,其输出仍然具有与单个 xi 相同的 magnitude bound,即
i=1∑nn1xi≍xi.
因此
Softmax(q1,⋯,qn)X=i=1∑nwixi≍xi.
Lemma 1对Attention输出头的阶进行了估计,保证了输入和输出的阶是相等的,Attention不会导致Model Update发生爆炸
Lemma 2 方差的阶的可加性
Var(X+Y)≍Var(X)+Var(Y)
Proof:
展开得
Var(X+Y)=E[(X+Y)2]−[E(X+Y)]2=E(X2)−E2(X)+E(Y2)−E2(Y)+2E(XY)−E(X)E(Y)=Var(X)+Var(Y)+2cov(X,Y)
Theorem 1 对于N层DeepNet结构 F(x,θ) , 每一层的DeepNet可表示为 xl+1=f(xl,θl)=LN(αxl+Gθl(xl)), θi∈{θ1,⋯,θ2N}
其中奇数参数是Selt-Attention的参数权重,偶数参数是FFN的参数权重。则有
∥ΔF∥≤i=1∑nαvi2+wi2∥θi∗−θi∥
基于最简化的情况,Self-Attention Layer 与 FFN layer 都视为 Gθ(xl)≍vlwlxl, 则每一个Layer的递推输出为
xl+1=f(xl,θl)=Var(αxl+Gθl(xl))αxl+Gθl(xl)≍(α2+vl2wl2)Var(xl)(α+vlwl)xl
根据Lemma 1, Var(xl)≍Var(x0)=1, 故
xl+1=f(xl,θl)≍α2+vl2wl2α+vlwlxl
因此
∂xl∂fl≍α2+vl2wl2α+vlwl
视 θl=(vl,wl)
∂θl∂fl≍(α2+vl2wl2)23αxl(α−vlwl)(wl,vl)
因此可展开Layer Model Update
∥ΔF∥=∥f(x2N∗,θ2N∗)−f(x2N,θ2N)∥=∥∂xl∂f(x2N,θ2N)(x2N∗−x2N)+∂θl∂f(x2N,θ2N)(θ2N∗−θ2N)∥≤∥∂xl∂f(x2N,θ2N)∥∥x2N∗−x2N∥+∥∂θl∂f(x2N,θ2N)∥∥θ2N∗−θ2N∥≍α2+v2N2w2N2α+v2Nw2N∥x2N∗−x2N∥+(α2+v2N2w2N2)23αx2N(α−v2Nw2N)∥(w2N,v2N)∥∥θ2N∗−θ2N∥∣≤∥x2N∗−x2N∥+(α2+v2N2w2N2)23αx2N(α−v2Nw2N)w2N2+v2N2∥θ2N∗−θ2N∥≍∥x2N∗−x2N∥+αw2N2+v2N2∥θ2N∗−θ2N∥
递推得
∥ΔF∥≤i=1∑2Nαwi2+vi2∥θi∗−θi∥
由于每一个wi,vi 的初始化都与scaling factor β 相关, 因此整个Model Update 的 Bound 能通过 α,β 控制,我们能通过设计这两个值的大小实现稳定训练Deeper的Network且保证收敛
